
Background
With the popularity of the Internet, cybersecurity incidents are becoming more and more frequent. And one of those attacks that everyone may encounter is phishing (Dhamija, R., 2006). Phishing can reach victims via different attack approaches, such as text messages and emails. Victims are then directed to malicious websites, which hijack the devices through deceiving victims to enter sensitive information or downloading malware. Malicious website is a key component in phishing attack, which is hosted on Internet domains. However it is very difficult for cybersecurity vendors to detect such domains, because attackers continuously update domain names and IP addresses (Holz, T., 2008) to evade from detection and blacklist. Therefore, it has been a common case where many users have already been victimized before a malicious domain is blocked. This highlights the importance to detect malicious domains at their early stage.
Method
This project used a graph-based method to assess the risk level of the domain-related information from Domain Name System ( DNS ) and registrar. DNS is a fundamental Internet infrastructure which translates easy-to-remember phrase-based URLs to digitbased IP addresses to ease the access of website for everyone. Modern DNS infrastructures are generally installed with monitoring software/hardware to record the recent activities of different domains, which can be used for risk assessment.
Challenge
Hackers are never static, they change domain names frequently, also register or delete domains on different DNS servers. Alternatively, they use the sub-techniques like Double Flux (change the domain name and IP at the same time) (Lovet, G., 2008) and Canonical Name to obfuscate the detection. The randomness of hackers actions makes manual rule-based evaluation inefficient. Fortunately, the DNS infrastructures can provide massive records of these domains such as AS number, IP change and nameserver change (Bilge, L., 2011). Therefore, we hope to find some clues from this data. Unfortunately, the large scale of DNS records collected from all over the world, and the weakly structured, multi-modal and variable-length data contained in DNS records and registrar information makes it difficult for traditional machine learning algorithms to be used directly.
Ideas
“With theses DNS records, is it possible to generate detection rules for malicious domains?” According to the expert knowledge from our industrial partner, the answer is positive. Infrastructure-as-a-service is popular in today’s cyberattacks. Criminals often rent some infrastructures to conduct attacks. Some clues about these infrastructures may be found in DNS records so it may be feasible to generate rules to detect malicious domains.
Algorithm in Brief
Domains are related with each other because some of them share common attributes such as IP addresses or registrars. An algorithm -community detection- (or graph partition, Fortunato, S., 2010) will be used in this project to identify for domain partitioning rules. First, two types of rules are defined. One is called Aggregation Logic and the other is Common Attribute Condition. The purpose of the algorithm is to search for aggregation logic from massive data, and after the aggregation logic is applied to the data, the graph will be divided into several subgraphs. The attributes shared by all domains in a subgraph is called common attribute condition.
For example, there are 3 domains, x.com, y.com and z.com, where x.com has attribute A = {1, 2, 3} and attribute B={4, 5, 9}, y.com has attribute A = {2, 3}, has attribute B={5, 9}, z.com has attribute A = {1, 3} and attribute B = {4}. An example aggregation logic is “at least two shared A attributes and two shared B attributes”. This will result in a subgraph that contains domain x.com and y.com. The common attribute condition is “A={2, 3} and B={5,9}”. Both aggregation logic and common property condition can be effective to check if a new domain is related to known malicious domains. Since the common attribute condition clearly defines the attributes shared by the domains in a subgraph, in actual use, a hash table can be used together to rapidly check if a new domain is malicious. For aggregation logic, it can be used to investigate whether a batch of new domains correlate known malicious domains.
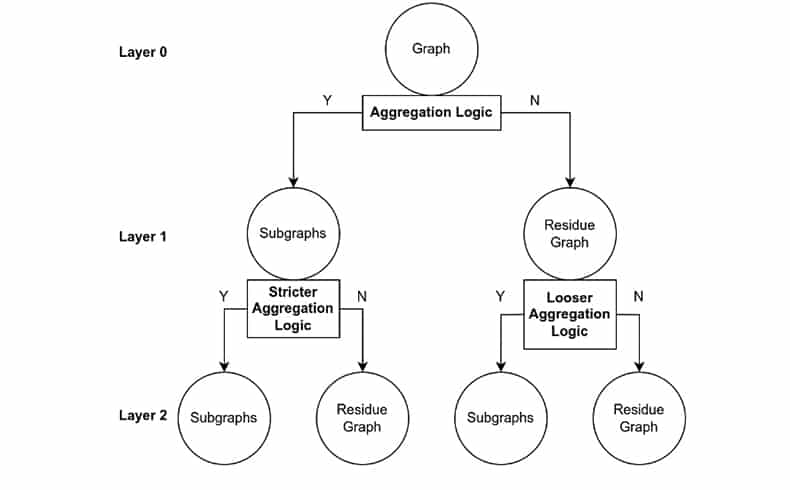
Innovative Algorithm Design
The core of the algorithm is how to search for effective aggregation logic. In this project, Graphlet was proposed. Graphlet is a multi-resolution, hierarchical graph partitioning algorithm inspired by wavelet packet analysis (Yen, G.G. 2000). The idea of Graphlet is to greedily and incrementally search for valid aggregation logics. Each layer will use different aggregation logics for creating subgraphs (the logic of the higher layer is stricter than the lower layer, until the subgraph produces an empty set).
The domains will be divided into subgraphs according the aggregation logic, and those that do not satisfy the aggregation logic will be left in a residual graph. For residual graphs, Graphlet uses a more relaxed aggregation logic for further partitioning. Ultimately, this forms a multi-resolution tree structure. How to add aggregation logic at different layers is determined by a optimized method. For the labeled domain data, we combine the information theory-related minimum description length criteria and task-dependent classification accuracy to evaluate the sparsity and effectiveness of subgraphs. After the entire Graphlet tree is completely constructed, the common attribute condition of each subgraph at each layer can be extracted and used to assess the domain risk.
How to use
When a new domain is observed, common attribute condition can determine whether this domain is related to any previous subgraph. If it is related to a malicious subgraph (the majority of domains in the subgraph are malicious), then this domain is very likely to be malicious. If a domain is related to multiple subgraphs, the subgraph with the best condition matching is selected for assessment.
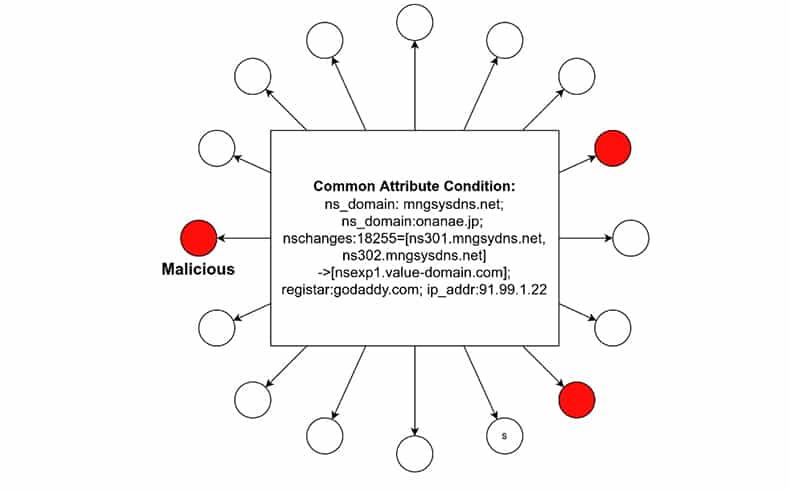
Aggregation logic is used for correlating a batch of new domains with known domains. First, some known malicious domains will be added to the set of new domains, as anchors. Then, graph partitioning will be performed on all domains (new + old anchors) using aggregation logic. If newly generated subgraph is mixed with known malicious domains (red), the new domains in the same subgraph are likely to be malicious.
This project is sponsored by EI Innovation Partnership Program & the EI Technology Gateway Program and is a collaboration between the Software Research Institute Research group at TUS, SilentPush and the COMAND Technology Gateway based at The Technical University of the Shannon, .
For more information on COMAND check out their website and follow them on Twitter.
Reference
Holz, T., Gorecki, C., Rieck, K. and Freiling, F.C., 2008, February. Measuring and detecting fast-flux service networks. In Ndss.
Dhamija, R., Tygar, J.D. and Hearst, M., 2006, April. Why phishing works. In Proceedings of the SIGCHI conference on Human Factors in computing systems (pp. 581-590).Vancouver
Lovet, G., 2008. Cybecrime is in a state of flux. Network Security, 2008(8), pp.6-8.VancouverBilge, L., Kirda, E., Kruegel, C. and Balduzzi, M., 2011, February. Exposure: Finding malicious domains using passive DNS analysis. In Ndss (pp. 1-17).VancouverFortunato, S., 2010. Community detection in graphs. Physics reports, 486 (3-5), pp.75-174.
Yen, G.G. and Lin, K.C., 2000. Wavelet packet feature extraction for vibration monitoring. IEEE transactions on industrial electronics , 47 (3), pp.650-667.


